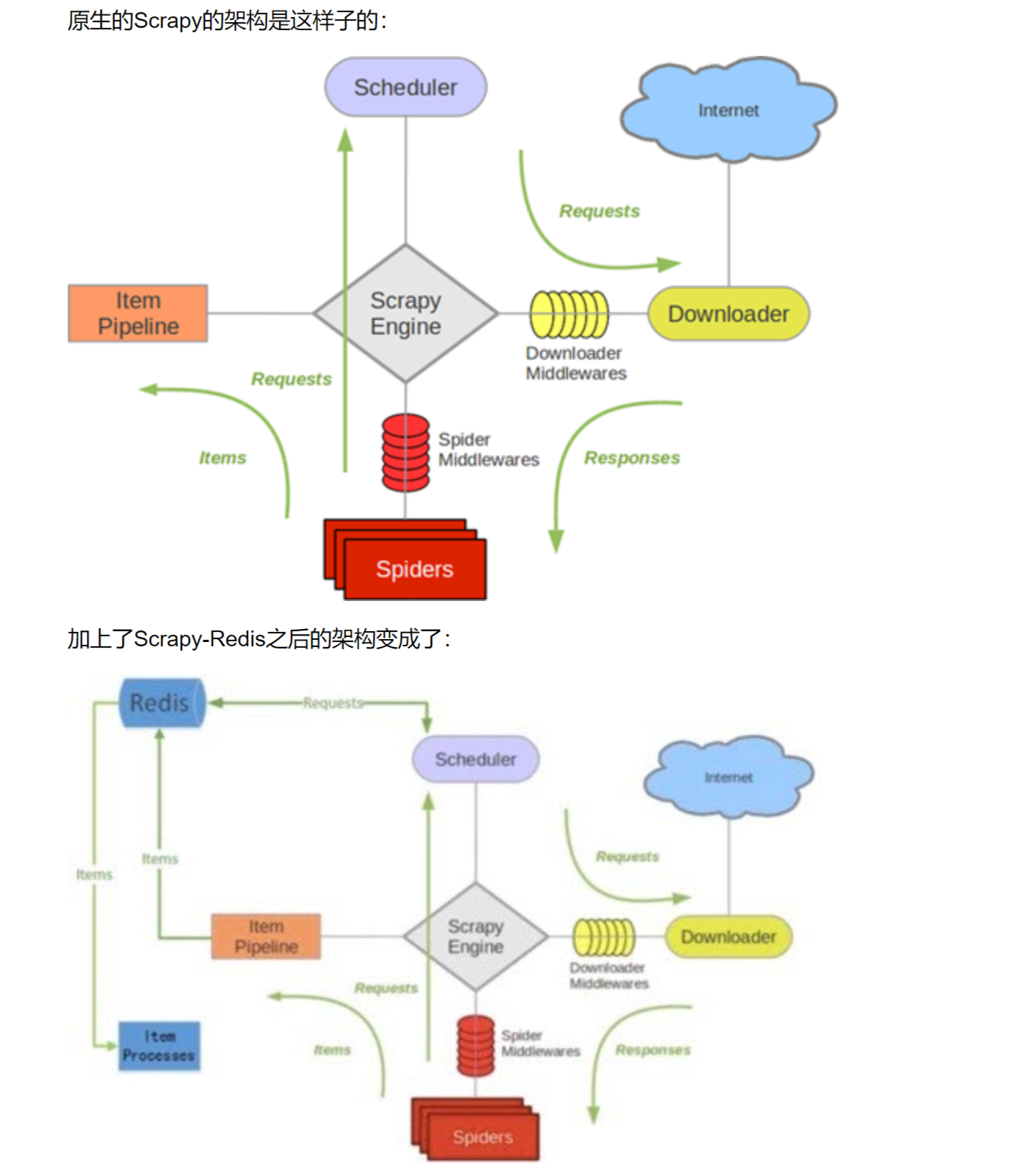
这里主要用的是Scrapy-redis,下面是框架图
因为手机系列多,变化相对较快,爬取的都是京东搜索手机关键字会出现很多品牌(如下图),我从中选择了产品比较多的牌子组成一个关键字list,phone_cates = ['华为','小米','Apple','三星','魅族','锤子','一加','vivo','努比亚','OPPO','360','苹果','中兴','乐视','美图','诺基亚','金立','索尼','酷派','ZUK','联想','HTC','飞利浦'],

获取URL
这里爬取需要的URL有两个,一个是商品的页面,一个是商品的评论。
商品的页面可以简单的搜索几次。很容易就能看出,大概是这个样子
https://search.jd.com/Search?keyword={}&enc=utf-8&page={}
评论页面的URL需要自己找,按F12打开控制台,然后随便点击一下评论中的页码,评论部分会刷新,这时候就选择刚才点击事件的时间段,然后找productPageComments.action这个名字,点击后可以看到Request URL,这个就是评论的 URL,可以打开这个URL,是一个json格式的内容,评论就是通过这个请求来获取数据动态刷新的

去掉不需要的参数后,得到的评论URL是这个样子的https://club.jd.com/comment/productPageComments.action?productId={}&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0
评论内容json分析
json 只能爬到前100页的内容,这个json 嵌套的比较深,爬取内容也只取评论中的一部分,取了一条评论说明下
'_id', 2100101691
'uid', 7d6f6d60-21c8-4cad-8c25-e64545429f08
'iid', 3888240
'productName', 华为 Mate 9 4GB+32GB版
'color', 月光银
'size', 移动联通电信4G手机 双卡双待 陶瓷白 64GB
'creation_time', 2016-12-07 13:57:55
'user_level', 钻石会员
'score', 5
'days', 13
'afterDays', 0
'userClientShow', 来自京东iPhone客户端
'userClient', 2
'comment' #下订单后三天 顺丰炔递就送到。外箱包装牢固 产品完美无瑕 白色机身漂亮 系统稳定 拍照漂亮 这是一次100%满意购物!
商品ID获取
当手机品牌关键字和页码补充完整后,爬取下来的是一整页的商品,大概是60个不同的商品,每个商品对应一个ID,下图是一个商品的代码,其中很容易找到商品的ID

有些关键字的页码数太大的时候就会出现不是手机或者评论过少的商品,所以只怕每个关键字的前十页,
爬取评论
这样通过关键字列表和页码就能爬取到商品ID(具体怎么做,见代码,可以用这个插件只下载你需要的代码),然后通过这些商品ID和页码数取爬取商品的评论。思路大概就是这样子。

改进和遇到的问题
- scrapy-redis 支持断点续爬
- 改进的主要是用高匿IP去爬取,开启多线程